One of the main parts of SynXBio Inc. is the use of different computer programs and packages. As we develop the packages, programs and notebooks (Jupyter or R-markdown) will be placed on an appropriate repository for others to develop or use in accordance with GPLv3/CC-BY-SA license. Some of the packages written are to improve the overall medical community. Some examples are the TDTK and a free predictive epidemiology R markdown documents. SynXBio Inc. is in the development stages of several packages that are being tested internally. The majority will be released as “free software,” however some internal packages along with specific algorithms will remain internal to the company.
To use the R based programs/packages several options exist. They are developed using R, EMACS/ESS or R-studio. For programs written in Python the most current form of Anaconda, miniconda or mamba should be installed and used according to the documentation. The development of these packages are done using a standard laptop or desktop from System76 running Pop!_OS and can be performed by anyone with a fairly recent computer on nearly all OS’s. For parallel processing or items needing a GPU, an appropriate computer is needed and there are no alternative functions. Due to certain non-package requirements, some functions in the “synxrna” package may not be available on the new Mac M-type (ARM structure) computers. If you have a Mac with ARM architecture please check to see if the ViennaRNA package has a OS specific compiled package and follow the installation instructions.
SynXRNA package (R package)
This is a package written in R for SynXBIo Inc. for the generation of novel biomolecules to treat disease. It is currently in testing and is expected to be submitted 1Q2023. Check the blog section for different uses of the synxrna package. One of the synxrna functions was demonstrated in a two part blog entry on the use of a tangential (i.e. not RNA specific) function to make ASPE oligos for the detection of mutations using the Luminex multiplex assay system.
A simple workflow of simulation –> feature selection –> laboratory based R&D is how SynXBio Inc. is discovering the next generation of therapies.
Medical Registrar Data Analytics (R package)
This project started as the Trauma Director Took Kit (TDTK) to help trauma centers that maintain an patient registry to analyze their patient population. This package is a legacy package that waiting on volunteers, data sets to be randomized and then submit to CRAN. For more information on the package you can watch a Free software Foundation 2019 LibrePlanet presentation or visit the GitHub repository. NOTE: The LibrePlanet presentation requires a media player that can play FSF/GPL verified content. This means no Digital Resource Management (DRM) or other items that may limit user freedoms.
Open Predictive epidemiology (R-markdown document(s))
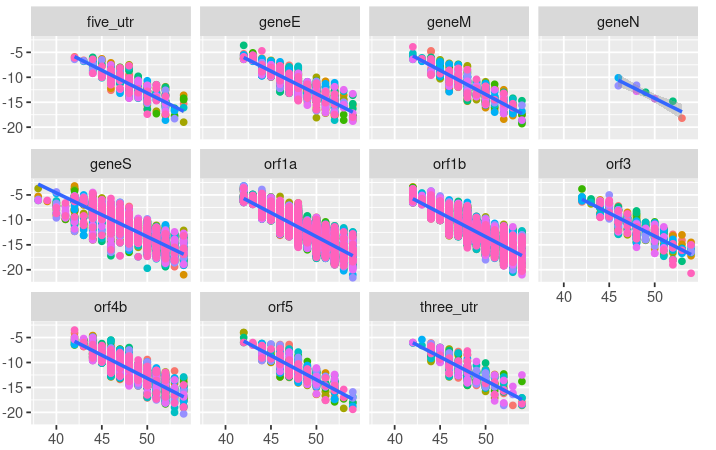
Sometime the old models are good a showing the past impact of an infectious disease (see the figure below from the 1872 NYC ID report). Classical epidemiology uses moving average to “smooth” the data. However, this can remove information for the direction of the “averaging” window. To augment the classical epidemiological reports, predictive time-series modeling is needed. There are several methods such as exponential growth or ARIMA that can make predictions for the next time period. These predictions can provided clinicians and public health officials actionable prediction for an infectious disease outbreaks to hopefully minimize impact. This project is in a very basic format and requires R and R markdown (R-studio is the easiest) to use the documents. As an example a basic “state-wide” analysis of the NYT-Covid data set was done. The geo-spatial analysis was done on a county level due to the data set but any geographic level is possible. In this document exponential growth, linear regression, case difference linear regression, naive, drift and ARIMA predicative modeling is done to aid public health officials predict the next “hot spots.” To download the basic state_id_report.rmd click the link or got GitHub. This is meant only as a basic learning document licensed as CC-BY-SA and can be modified and used with whatever data set chosen. The goal is to take standard methods used for over a century and provide basic predictive analytics in a free document.
